# 지난 주 크게 두 가지 변경사항이 있었다.
하나는 데이터셋 변경, 다른 하나는 PE format 추출 방법 변경. 기존에 EMBER 데이터셋 사용에서 KISA 데이터셋 사용으로 바꾸었고, 메모리에서 PE format 읽는 걸 실행파일 바이너리에서 PE format읽는 것으로 바꾸었다.
# 실행파일에서 읽는 것으로 바꾼 뒤, 에이전트 개발은 속도가 붙어 이번 주 내에 개발이 완료 되었다.
내가 만든 파이썬 화이트 리스트 코드와 C 에이전트와 embedding 도 완료했다. C랑 Python이랑 embedding 하는 게 좀 삽질이 있었지만 잘 마칠 수 있었다. 이것도 따로 정리를 하긴 해야겠다 ㅋㅋㅋㅋ (하면서 자료가 너무 없어서 꼭 한 번 정리를 해야겠다고 생각함)
- "실행되는 프로세스 글로벌 후킹 --> 실행파일에서 PE 추출 --> python 전처리 코드 활용해서 데이터 가공" 까지 구현을 했다.
근데 여기서 새로운 문제가 발생!
우리는 딥러닝 모델을 Tensorflow와 keras를 사용했는데, 이 API들은 64bit 아키텍쳐에서 구동이 가능했다. 32bit는 안되는겨... 하.. ㅋㅋㅋㅋㅋ 근데 우리는 오래된 레거시 환경을 가정하고 개발을 해서, win xp 나 7의 32bit 환경에서 개발했다. 따라서 Tensorflow와 Keras를 32bit로 다시 컴파일을 하던가.... 서버를 두고 운영하던가 해야 했다. 서버를 두고 운영하는 것은 전처리 된 데이터를 서버로 넘기면, 서버에서 딥러닝으로 예측한 결과값을 넘겨주는 CS 구조로 운영하는 방법이다. 시간 관계 상 후자를 택해서, Flask를 활용해 서버를 구현했다.
이로써, 에이전트는 개발 완료!
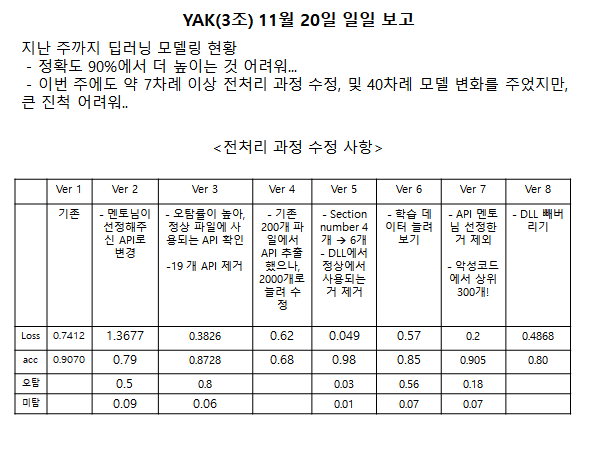
# 딥러닝 모델도 90퍼 정도 정확도가 나오고 있었다.
멘토님께서 90퍼는 10개중에 1개가 틀린다는건데 어따 쓰냐며,, 99퍼를 만들라고 하셨다. 그래서 더 정확한 feature를 선별해내려고 계속 바꿔보고, 전처리 코드도 계속 수정하고, 예측 해보고 했다. 이 과정이 ㄹㅇ 힘들었음 ㅠㅠ
우선 데이터가 많으니까 전처리 과정 시간이 오래걸리는 거, 학습 시켰을 때 결과가 지 맘대로 나오는 게 힘들었음 ..
세명~네명이서 나눠서 전처리 돌리고, 모델 바꿔보고 수십 수백번을 돌려봐도.... 잘 안됐음 ㅠㅠ
# 멘토님들께 보고드린 일일보고 파일..
우선 에이전트 개발 완료해서 시현 영상 보여드리니까 굉장히 좋아하셨다. 다만, 정상인데 악성이라고 탐지하는 오탐이 너무 높아서, 딥러닝 feature나 전처리 과정을 많이 수정해야 할 것 같다....


'[혁신성장 청년인재] 인공지능을 활용한 보안전문가 양성과정' 카테고리의 다른 글
| DAY 112 : 마지막 날 | 프로젝트 발표 | 혁신성장청년인재집중양성 후기 | IT국비교육 후기 | 멀티캠퍼스 국비교육 | 국비교육 장단점 (4) | 2020.12.10 |
|---|---|
| DAY 102 ~ 111 : 프로젝트 정리 | 프로젝트 보고서 작성 | 프로젝트 발표준비 (0) | 2020.12.10 |
| EMBER 데이터셋 불러오기 | Colab 에서 내 드라이브 마운트해서 데이터 저장 (0) | 2020.12.10 |
| DAY 91~95 : 프로젝트 둘 째 주 | 두 가지 난관에 봉착하다... | EMBER dataset | 메모리에서 PE format 읽기 (3) | 2020.12.10 |
| DAY 85 ~ 90 : 프로젝트 첫 주 | 착수보고서 | 일일보고서 작성 (0) | 2020.12.10 |



